




I. Réception de données ? Quelles données ?▲
Comme vu de par son prototype précédemment, l'appel à recv permet de récupérer jusque len octets de données.
Comment ça marche ? On ne s'en soucie pas, c'est le fonctionnement interne de TCP et dans sa boîte noire. Tout ce qu'il faut savoir pour le moment, c'est que l'appel à recv ne lit pas des données du réseau directement, ce n'est pas possible et c'est le matériel qui s'en charge, mais depuis un tampon système où sont stockées les données reçues de l'ordinateur distant après avoir réalisé toutes les manipulations nécessaires pour s'assurer qu'elles sont cohérentes avec ce qui a été envoyé, dans leur quantité et le bon ordre. Quand ces manipulations sont réussies, le système met les données à disposition de l'application qui peut en extraire une quantité donnée via recv.
Comment alors peut-on savoir si les données extraites sont le résultat d'un ou plusieurs appels à send ? C'est impossible !
Exemple concret : si A envoie à B « salut » puis « comment va ? » en deux temps (via deux appels à send), lorsque B appellera recv il pourra extraire « salutcomment va ? » si toutes ces données sont reçues et disponibles. Du point de vue de B, on n'a absolument aucune idée s'il s'agissait d'un ou plusieurs envois, ce qui peut faire une grosse différence (par exemple dans ce cas : « salut » et « comment » se retrouvent collés - ce qui n'est pas très grave dans cet exemple simpliste, mais peut entraîner de gros problèmes en pratique) quant au traitement à faire sur notre tampon.
II. Créer son protocole▲
On doit alors ajouter un minimum de logique logicielle autour de nos données. Mettre en place son protocole, son formalisme, ses règles d'échange de données.
D'abord un peu de vocabulaire pour s'assurer que l'on parle la même langue. Nous parlons généralement de paquet, ou message, réseau. Le paquet sera désormais notre unité d'échange, il s'agit d'un amas de données envoyées/à envoyer à l'ordinateur distant. Un mot, une phrase, le contenu d'un fichier, chacun de ces éléments sera envoyé par paquets. On enverra toute donnée sous forme d'un paquet en TCP, que l'on peut découper manuellement, par exemple si le paquet résultant était trop important, chaque fragment sera alors un paquet nécessaire à reformer la donnée finale.
Il devient donc évident qu'il nous faut un moyen de délimiter les paquets afin d'être capable de les retrouver si l'appel à recv nous retourne plusieurs paquets de données à notre insu, ou pour limiter les données à extraire de recv à la longueur du paquet attendu.
Il existe en gros trois possibilités :
- utiliser des paquets de taille fixe ;
- utiliser un délimiteur, une suite d'octets, à la fin d'un paquet qui indique sa fin ;
- indiquer au destinataire la taille des données à traiter, en préfixant le paquet de sa taille.
La première option est rejetée de par son inefficacité, en dehors du cas particulier où il s'agira de la meilleure option, et la perte énorme que ça engendre en général. Il faut que la taille choisie soit suffisante pour le paquet le plus gros, donc le gaspillage de mémoire est d'autant plus important que le paquet est petit.
La seconde option est risquée : il faut pouvoir être sûr à 100 % que la suite d'octets choisie ne sera jamais présente dans un paquet. Notamment si vous comptez transférer des fichiers, ou du binaire de manière générale, comment vous en assurer ?
Reste la troisième solution, celle que j'ai toujours employée et que nous utiliserons dans ce cours.
III. Mise en place du protocole▲
La solution retenue est donc de préfixer chaque paquet de sa taille. Pour y parvenir, nous pouvons au choix mettre le nombre en texte plein, ou le sérialiser dans sa forme binaire. Et dans ce dernier cas, quelle taille doit être utilisée ?
L'idée d'utiliser du texte est généralement alléchante, pourtant c'est de loin la moins efficace. Si vos données font 50 octets, vous devrez stocker « 50 », et le délimiteur de fin de chaîne, soit trois octets avant que les données intéressantes de votre paquet ne commencent.
Nous pouvons faire la table suivante pour connaître la taille du paquet en fonction de la longueur du préfixe :
| Intervalle de préfixe | Taille du préfixe (octets) | Quantité de données min | Quantité de données max | Taille totale du paquet min (octets) | Taille min formatée | Taille totale du paquet max (octets) | Taille max formatée |
| 1-9 | 2 | 1 | 9 | 3 | 3 o | 11 | 11 o |
| 10-99 | 3 | 10 | 99 | 13 | 13 o | 102 | 102 o |
| 100-999 | 4 | 100 | 999 | 104 | 104 o | 1003 | 0,98 ko |
| 1000-9999 | 5 | 1000 | 9999 | 1005 | 0,98 ko | 10004 | 9,77 ko |
| 10000-99999 | 6 | 10000 | 99999 | 10006 | 9,77 ko | 100005 | 97,66 ko |
| 100000-999999 | 7 | 100000 | 999999 | 100007 | 97,66 ko | 1000006 | 976,57 ko |
| 1000000-9999999 | 8 | 1000000 | 9999999 | 1000008 | 976,5 ko | 10000007 | 9,53 Mo |
Intéressons-nous à l'intervalle 100-999. Avec un préfixe de quatre octets, nous pouvons envoyer jusqu'à 1003 octets. Ce qui n'est certes pas mal, mais pas forcément évident pour transférer un fichier par exemple. Nous devons monter à huit octets pour pouvoir envoyer un maximum de 9.53 Mo de données.
Alors que quatre octets et huit octets peuvent être représentés respectivement par un entier 32 bits (int32) et 64 bits (int64).
Nous savons aussi que notre taille est forcément positive, il s'agira donc d'entiers non signés (uint32 et uint64). Pour lesquelles les intervalles de valeurs iront jusque 4 294 967 295 pour uint32 max permettant d'envoyer jusque 4096 Mo, et 18 446 744 073 709 551 615 pour uint64 qui représenteraient 16 777 216To. Ils nécessiteraient respectivement 10 et 20 octets, plus le délimiteur de fin de chaîne soit 11 et 21 octets, si on les représentait sous forme de chaîne. Soit un gâchis de 7 et 13 octets. Mais envoyer autant de données est de toute façon farfelu !
Pour ces raisons, nous opterons finalement pour un uint16, codé sur deux octets pour un maximum théorique de 64 ko par paquet. Il s'agit d'une taille déjà colossale pour un paquet, et si vous décidez d'envoyer une information plus importante que ça (un fichier de plusieurs Mo, ou Go, par exemple) vous devriez de toute façon gérer ça finement et manuellement par souci de quantité de ram utilisée entre autres.
IV. Puis-je vraiment envoyer 64 ko de données ?▲
Oui et non. Il faut maintenant comprendre plus précisément le fonctionnement de TCP par le système.
Comme indiqué en début de cette partie, recv récupère les données d'un tampon fourni par le système. Ce tampon est appelé TCP window. Ce tampon n'est bien entendu pas illimité, et sa taille dépendra de la configuration du système, que l'on retrouvera sous l'appellation de TCP window size.
La norme TCP indique que la taille de ce tampon est codée sur 16 bits (2 octets), et donc que la taille maximale théorique est de 64 ko (https://tools.ietf.org/html/rfc7323#section-1.1). Mais il s'agit d'une taille maximale et chaque système est libre d'utiliser une taille moins importante, notamment sur les appareils mobiles où ce sera le plus souvent le cas.
Il existe également un autre paramètre TCP window scale permettant de multiplier cette taille sur la plupart des systèmes. Là encore, il s'agit de configuration système. Ce multiplicateur sera utilisé principalement pour configurer des réseaux spécifiques, rien qui ne nous intéresse et que l'on puisse réellement utiliser donc.
Si par hasard (ou malheur) votre tampon système se retrouve plein, aucune nouvelle donnée ne pourra être réceptionnée par le système tant que vous n'aurez pas fait appel à recv pour en extraire et libérer des données, ou libérer le socket correspondant. Ayant pour effet de bloquer l'envoi par les ordinateurs distants, voire de vous déconnecter. Dans le pire des cas, les ordinateurs distants peuvent également mettre trop de données en attente d'envoi dans leur système, bloquant également tout envoi de données de leur part à leurs destinataires (ce qui peut inclure d'autres machines que la vôtre).
Cette fenêtre influera également sur le débit de données que l'on a par la formule
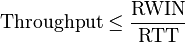
où Throughput est ce débit, RWIN la taille du tampon système (défini par TCP window et TCP window scale) et RTT le Round-Trip Time, le ping.
Donc s'il est en théorie possible d'envoyer un message de 64 ko, en pratique on n'a que rarement, voire jamais, besoin d'envoyer autant de données en un unique paquet, vous ne devriez donc pas vous retrouver dans ce genre de cas particulier de si tôt. Et si le cas se présente, si vous souhaitez envoyer un fichier par exemple, il suffira de veiller à découper le paquet en plusieurs parties dans la couche logicielle, ou votre moteur réseau, afin de le reconstruire à destination.
Training Time ! Lancez ou compilez le TD 03. Il s'agit d'une version modifiée du serveur de la partie précédente, qui vous retournera votre phrase en mélangeant les mots de celle-ci, mais en prenant en compte le protocole que l'on a introduit dans cette partie.
V. Proposition de corrigé▲
Nous continuons d'itérer sur notre classe TCPSocket.
Améliorons l'interface de Send et Receive afin d'être plus que de simples wrappers.
Je propose l'interface suivante :
bool Send(const unsigned char* data, unsigned short len);
bool Receive(std::vector<unsigned char>& buffer);L'idée étant que ces fonctions retournent false en cas d'erreur, true sinon. Notez également le passage à de l'unsigned char dans les types.
Petit aparté avant de voir l'implémentation que je propose.
V-A. Pourquoi unsigned char ?▲
Le fait est que le char, dans la norme, n'est pas défini comme étant signé ou non signé (http://www.open-std.org/jtc1/sc22/open/n2356/basic.html#basic.fundamental). Le fait que le char soit en fait un signed char ou unsigned char est laissé au choix du compilateur.
Manipuler des unsigned char permet donc de lever cette ambiguïté, tout en permettant d'utiliser l'un ou l'autre (ou tout autre type) via des conversions (static_cast, reinterpret_cast). Quels que soient la plateforme ou le compilateur utilisé, nous communiquerons via des unsigned char avec l'application.
Je trouve également d'un point de vue personnel qu'il est plus simple de réfléchir en termes d'unsigned char, sur un intervalle [0;255] qu'en termes de signed char [-128;127], que je dois rechercher quasi systématiquement pour sortir de la confusion « [-127;128] ou [-128;127] ? ».
Au niveau de l'implémentation, commençons par le plus simple, le Send :
2.
3.
4.
5.
6.
bool TCPSocket::Send(const unsigned char* data, unsigned short len)
{
unsigned short networkLen = htons(len);
return send(mSocket, reinterpret_cast<const char*>(& networkLen), sizeof(networkLen), 0) == sizeof(networkLen)
&& send(mSocket, reinterpret_cast<const char*>(data), len, 0) == len;
}
Comme convenu, notre protocole commence par envoyer la longueur des données, puis les données à proprement parler.
Les conversions nécessaires pour le passage des paramètres à l'API sockets, et enfin on s'assure que les données envoyées l'ont été avec succès en vérifiant que les tailles mises en file d'envoi sont celles attendues.
La seule difficulté réside dans la conversion de ladite longueur dans l'endianness réseau avec la fonction htons vue dès la première partie du cours. C'est facilement oubliable.
Voyons maintenant l'implémentation du Receive qui, sans être insurmontable, présente une subtilité :
2.
3.
4.
5.
6.
7.
8.
9.
10.
11.
12.
13.
14.
15.
16.
17.
18.
19.
20.
21.
22.
23.
24.
25.
26.
27.
28.
bool TCPSocket::Receive(std::vector<unsigned char>& buffer)
{
unsigned short expectedSize;
int pending = recv(mSocket, reinterpret_cast<char*>(&expectedSize), sizeof(expectedSize), 0);
if ( pending <= 0 || pending != sizeof(unsigned short) )
{
//!< Erreur
return false;
}
expectedSize = ntohs(expectedSize);
buffer.resize(expectedSize);
int receivedSize = 0;
do {
int ret = recv(mSocket, reinterpret_cast<char*>(&buffer[receivedSize]), (expectedSize - receivedSize) * sizeof(unsigned char), 0);
if ( ret <= 0 )
{
//!< Erreur
buffer.clear();
return false;
}
else
{
receivedSize += ret;
}
} while ( receivedSize < expectedSize );
return true;
}
Vous pouvez remarquer immédiatement la symétrie logique avec le Send.
On commence par lire notre en-tête, la taille attendue des données qui vont suivre et former notre paquet. On s'assure que tout s'est bien passé, sinon inutile d'aller plus loin et on peut retourner false immédiatement pour indiquer à l'utilisateur qu'un problème est survenu.
Ensuite, on lit les données. Et alors qu'on pourrait s'attendre à un simple appel à recv, celui-ci se trouve dans une boucle.
recv ne fait que transférer des données depuis un tampon système dans notre propre tampon passé en paramètre, en prenant en compte la taille maximale de l'espace disponible que l'on lui indique. Et il s'agit bien de la taille maximale à extraire, et non de la taille attendue. recv n'a aucune connaissance du fait que nous allons effectivement recevoir X données. Si nous demandons la réception de X données, mais qu'il n'en a déjà que Y disponibles, avec Y <= X, il remplira notre tampon de ces Y données et nous retournera cette valeur. Si nous voulons vraiment attendre les X données, nous le réalisons à l'aide de cette boucle, dans la logique logicielle. Il ne bloquera pas jusqu'à remplir le tampon qu'on lui fournit.
Dans l'absolu, cette même boucle devrait être mise en place pour la réception de l'en-tête. Inutile d'encombrer le code pour l'instant, supposons, sans grande erreur, que l'envoi des deux octets d'en-tête sera toujours faisable sans découpage par la couche réseau pour rendre cette opération possible en un seul appel à recv.
Et bien entendu pour chaque appel à recv, il convient de vérifier qu'aucune erreur n'est survenue.
Télécharger les codes sources du cours
| Article précédent | Article suivant |
|---|---|
| << TCP - Envoi et réception | TCP - Premiers-pas en tant que serveur >> |