




I. Qu'est-ce qu'un thread ?▲
Un thread permet de paralléliser du code, son exécution, au sein d'un programme tout en partageant la mémoire virtuelle du programme, mais possédant chacun sa pile d'appels.
En général, le code exécuté dans la fonction main sera appelé le « main thread » ou thread principal, les threads que nous créerons seront des threads secondaires.
Puisque le code est exécuté en parallèle, les fonctions bloquantes ne seront pas un problème : seul le thread qui les exécute sera bloqué, le reste du programme pouvant continuer son exécution.
II. L'API thread▲
Les thread et mutex ont maintenant une API disponible dans la std : std::thread et std::mutex. Leurs documentations sont disponibles en ligne aux adresses respectives suivantes http://www.cplusplus.com/reference/thread/thread/ et http://www.cplusplus.com/reference/mutex/, et nous allons passer en revue l'essentiel à savoir ici même.
II-A. thread▲
std::thread possède un constructeur par défaut, surtout utile pour pouvoir gérer ses threads dans des collections comme std::vector, mais surtout un constructeur qui prend une fonction et des arguments en paramètres et lancera un thread l'exécutant. On pourra bien sûr l'utiliser avec une lambda également.
2.
3.
4.
5.
6.
7.
8.
9.
10.
11.
12.
13.
14.
15.
#include <thread>
#include <mutex>
#include <iostream>
void display(int start, int nb)
{
for (int i = start; i < start + nb; ++i)
std::cout << i << ",";
}
int main(){
std::thread t1(display, 0, 5);
std::thread t2([]() { display(5, 5); });
t1.join();
t2.join();
return 0 ;
}
Dont une sortie peut être

II-B. join▲
Dans l'exemple ci-dessus, vous avez pu constater l'appel à une méthode join. Cette fonction est bloquante jusqu'à ce que le thread ait terminé son exécution, dans notre cas jusqu'à ce que la boucle et l'affichage de chaque valeur ait été faite. Quand la fonction d'un thread est terminée, le thread est automatiquement terminé.
III. Synchronisation : le mutex▲
Avec le multi-threading vient les soucis de synchronisation, plus communément appelés « race-condition ». En effet, chaque thread est exécuté en parallèle, mais nous n'avons aucune assurance de l'ordre des opérations de chaque thread.
Pour en prendre conscience, essayez le code suivant :
2.
3.
4.
5.
6.
7.
8.
9.
10.
11.
12.
13.
14.
15.
16.
17.
18.
19.
20.
21.
22.
23.
24.
25.
26.
#include <thread>
#include <iostream>
int main() {
std::thread t1([]() {
for (int i = 0; i < 10; ++i)
{
std::cout << (i * 3) << " ";
}
});
std::thread t2([]() {
for (int i = 0; i < 10; ++i)
{
std::cout << (i * 3) + 1 << " ";
}
});
std::thread t3([]() {
for (int i = 0; i < 10; ++i)
{
std::cout << (i * 3) + 2 << " ";
}
});
t1.join();
t2.join();
t3.join();
return 0;
}
Lancez-le plusieurs fois à la suite et constatez que les résultats ne sont pas toujours identiques.
Par exemple avec deux exécutions d'affilée sur ma machine, j'obtiens :


L'accès à la console via std::cout est concurrentiel entre les threads. On ne maîtrise pas quand chacun y accède et y écrit, d'où les différents résultats ci-dessus. Dans certains cas, un accès concurrent n'est pas gênant, ici écrire dans la console dans un ordre à priori aléatoire, en tout cas non maîtrisé, ne dérange pas le programme. Mais dans certains cas, il peut s'agir d'une ressource critique qui nécessitera alors que les threads l'utilisant soient synchronisés, d'une ressource nécessitant d'être utilisée par un unique thread à la fois.
Pour synchroniser nos applications, nous pouvons avoir recours à un mutex. Les mutex sont maintenant disponibles dans la std avec std::mutex, std::recursive_mutex, std::timed_mutex et std::recursive_timed_mutex.
De manière générale, il est préférable de construire son application de manière à ce que le code soit synchronisé par construction. En effet, un mutex est un point de contention, utilisé pour que deux tâches ne puissent s'exécuter en parallèle. On verrouillera un mutex pour l'acquérir, les appels successifs ne pourront alors pas le verrouiller et devront attendre qu'il soit libéré. Il s'agit bel et bien d'une attente, donc de bloquer le thread en question.
Mais plutôt que de craindre ces objets, mieux vaut savoir les utiliser si le besoin se présente - et il se présentera pour sûr !
III-A. std::mutex▲
std::mutex est le plus simple d'entre eux. Il peut être verrouillé une seule et unique fois, chaque appel à lock supplémentaire attendra que le mutex soit déverrouillé via un appel à unlock avant de retourner. Il existe également la méthode try_lock qui permet, si le mutex est déjà verrouillé, et un appel à lock serait alors bloquant de retourner false directement. Si le mutex peut être acquis, il est verrouillé et try_lock retourne true.
On pourra ainsi modifier le premier code comme ceci :
2.
3.
4.
5.
6.
7.
8.
9.
10.
11.
12.
13.
14.
15.
16.
17.
18.
19.
20.
21.
22.
23.
24.
25.
26.
27.
28.
29.
30.
31.
32.
33.
34.
35.
36.
37.
38.
39.
40.
#include <thread>
#include <mutex>
#include <iostream>
int main() {
std::mutex lock;
std::thread t1([&lock]() {
lock.lock();
std::cout << "Dans le thread t1" << std::endl;
for (int i = 0; i < 10; ++i)
{
std::cout << (i * 3) << " ";
}
std::cout << std::endl;
lock.unlock();
});
std::thread t2([&lock]() {
lock.lock();
std::cout << "Dans le thread t2" << std::endl;
for (int i = 0; i < 10; ++i)
{
std::cout << (i * 3) + 1 << " ";
}
std::cout << std::endl;
lock.unlock();
});
std::thread t3([&lock]() {
lock.lock();
std::cout << "Dans le thread t3" << std::endl;
for (int i = 0; i < 10; ++i)
{
std::cout << (i * 3) + 2 << " ";
}
std::cout << std::endl;
lock.unlock();
});
t1.join();
t2.join();
t3.join();
return 0;
}
Pour produire cet exemple de sortie
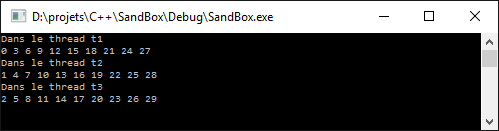
Où l'on constate que chaque thread effectue maintenant sa boucle complète, dû au blocage du mutex.
III-B. std::recursive_mutex▲
std::recursive_mutex est identique au std::mutex, mais peut être verrouillé plusieurs fois dans un même thread. Particulièrement utile si une fonction peut être amenée à se retrouver dans la callstack d'un thread qui aurait déjà verrouillé le mutex en question.
III-C. std::timed_mutex & std::recursive_timed_mutex▲
Les timed_mutex sont identiques aux mutex normaux vus ci-dessus et ont en supplément deux méthodes try_lock_for qui permettent d'essayer d'acquérir le verrou pendant un certain temps ou jusqu'à une date donnée.
Leur utilité étant moindre, nous ne nous attarderons pas sur ceux-là et n'utiliserons que des std::mutex et std::recursive_mutex dans le cadre de ce cours.
III-D. Interblocage ou deadlock▲
Avec l'utilisation des mutex en contexte multi-thread, il faut faire attention à ne pas se retrouver en situation de deadlock. La situation classique est d'avoir deux mutex, M1 et M2, et deux threads, T1 et T2, qui verrouillent chacun un mutex puis l'autre dans l'ordre inverse :
2.
3.
4.
5.
6.
7.
8.
9.
10.
11.
12.
13.
14.
15.
16.
std::mutex m1;
std::mutex m2;
std::thread t1([&m1, &m2]() {
m1.lock();
m2.lock();
std::cout << "Dans T1" << std::endl;
m2.unlock();
m1.unlock();
});
std::thread t2([&m1, &m2]() {
m2.lock();
m1.lock();
std::cout << "Dans T2" << std::endl;
m1.unlock();
m2.unlock();
});
En effet, puisqu'on n'a aucune assurance de l'ordre d'exécution du code, ce scénario peut (et va) se produire :
- T1 verrouille M1.
- T2 verrouille M2.
- T1 essaye de verrouiller M2 qui est déjà verrouillé.
- T2 essaye de verrouiller M1 qui est déjà verrouillé.
- Ni T1 ni T2 ne peuvent continuer leur exécution !
Bien entendu, dans la plupart des programmes la détection d'un deadlock ne sera pas aussi simple que le cas présenté ici. Certains peuvent s'avérer bien vicieux à déceler, impliquant plus de deux threads, plus de deux mutex, ou suite à une exception survenue avant l'appel à unlock…
III-D-1. lock_guard▲
Pour ce dernier cas, et pour une utilisation vraiment pratique et simplifiée des mutex, il existe un petit objet nommé std::lock_guard.
Cet objet prend un mutex en paramètre et le verrouille à sa création, puis se charge de le libérer à sa destruction. Il est ainsi très simple de limiter un verrou à un bloc de code, et en particulier en cas d'exception, early-return ou toute sortie prématurée du bloc, le verrou est également libéré automatiquement.
2.
3.
4.
5.
6.
std::mutex m;
{
std::lock_guard lock(m);
// m est maintenant verrouillé
}
// m n'est plus verrouillé
Le code du précédent exemple serait alors écrit ainsi :
#include <thread>
#include <mutex>
#include <iostream>
int main() {
std::mutex lock;
std::thread t1([&lock]() {
std::lock_guard guard(lock);
std::cout << "Dans le thread t1" << std::endl;
for (int i = 0; i < 10; ++i)
{
std::cout << (i * 3) << " ";
}
std::cout << std::endl;
});
std::thread t2([&lock]() {
std::lock_guard guard(lock);
std::cout << "Dans le thread t2" << std::endl;
for (int i = 0; i < 10; ++i)
{
std::cout << (i * 3) + 1 << " ";
}
std::cout << std::endl;
});
std::thread t3([&lock]() {
std::lock_guard guard(lock);
std::cout << "Dans le thread t3" << std::endl;
for (int i = 0; i < 10; ++i)
{
std::cout << (i * 3) + 2 << " ";
}
std::cout << std::endl;
});
t1.join();
t2.join();
t3.join();
return 0;
}III-D-2. unique_lock▲
Un autre objet similaire est le std::unique_lock. Cet objet peut s'y faire assigner un mutex et se charge de le déverrouiller à sa destruction s'il possède le verrou.
Son utilité pourra se trouver dans des fonctions sous cette utilisation par exemple :
2.
3.
4.
5.
6.
7.
8.
9.
10.
11.
{
std::mutex m;
std::unique_lock<std::mutex> lock(m, std::defer_lock);
if (!lock.try_lock())
{
// si le verrouillage n'a pas pu se faire, on quitte la fonction
return;
}
// ici m est maintenant verrouillé
}
// m est déverrouillé à la destruction de lock
D'autres constructeurs sont disponibles selon l'effet souhaité, comme acquérir le verrou à la construction (comme std::lock_guard), appeler try_lock sur le mutex à l'initialisation ou encore récupérer la gestion du verrou d'un mutex déjà verrouillé.
Pour plus de détails sur ceux-ci, je vous invite à lire la documentation http://www.cplusplus.com/reference/mutex/unique_lock/unique_lock/.
IV. Une autre API de threading : PPLX (C++ Rest SDK)▲
Une autre solution intéressante en guise de multi-threading peut être l'utilisation de la lib C++ Rest SDK, le namespace pplx, Concurrency Runtime, précédemment connu comme Casablanca.
Cette API permet l'écriture de tâches asynchrones, et particulièrement de les enchaîner, avec facilité.
La bibliothèque est disponible sur Github à l'adresse suivante https://github.com/Microsoft/cpprestsdk.
IV-A. pplx::create_task▲
Pour créer une tâche, le moyen le plus simple est d'utiliser la fonction create_task en passant en paramètre une lambda fonction qui sera exécutée en tant que tâche asynchrone. Cette fonction retourne un objet pplx::task<T> où T est le type de retour de la lambda fonction.
pplx ::create_task([](){ for (int i = 0; i < 10; ++i) std::cout<< "="<<i<<std::endl; });Écriture des nombres de 0 à 9 sous forme de tâche.
IV-B. task.then▲
Bien que l'interface d'une tâche permette de connaître son statut, d'attendre qu'elle soit terminée et récupérer son résultat, la vraie force de leur utilisation vient de la méthode then qui permet de les chaîner très simplement :
auto task = pplx ::create_task([](){ std::cout<<"premiere tache"<<std::endl; });
task.then([](){ std::cout<<"tache suivante"<<std::endl; });Ou on peut directement les chaîner sans utiliser de variable intermédiaire comme ceci :
pplx ::create_task([](){std::cout<<"premiere tache"<<std::endl; })
.then([](){ std::cout<<"tache suivante"<<std::endl; });Cas simple de tâches sans paramètres ni valeur de retour.
Si la tâche précédente retourne une valeur, celle-ci se retrouve dans les paramètres de la tâche suivante :
pplx ::create_task([](){ return 42; })
.then([](int result){ std::cout<<"la tache precedente a retourne "<<result<<std::endl; });Bien entendu il s'agira de réaliser une action asynchrone dans la première tâche afin d'utiliser son résultat dans la tâche chaînée.
Pour plus d'informations et les détails sur l'ensemble de l'API : https://microsoft.github.io/cpprestsdk/namespaces.html et https://github.com/Microsoft/cpprestsdk/wiki.